语法分析器的介绍
计算机科学和语言学领域里有种技术叫语法分析(Parsing),也叫Syntacticanalysis,说白了就是用一套规定的形式文法去剖析由单词(比如英文单词)排列组合而成的文本,目的是弄清楚这些单词之间的语法关系。这种分析工具通常出现在编译器或者解释器里,主要任务是检查输入的代码是否符合语法规范,并且把单词序列转换成一种结构化的数据形式,比如语法分析树或者抽象语法树。
在操作上,语法分析器通常会借助一个叫词法分析器的独立工具,从一串字符中把单词一个一个地分离出来,然后以这些单词作为处理对象。
实际应用中,语法分析器既可以靠程序员手动编写,也可以借助工具半自动生成。
词法分析器&语法分析器之C语言
词法分析器与语法分析器在C语言中的应用词法分析器:作为编译器的前端,词法分析器的主要任务是将源代码字符串分解成基础词法单元,即Token。
这些单元是编译器深入分析的基础。
在C语言中,这些单元涵盖诸如关键词(如if、else、while等)、标识符、常量、界符(如括号、分号等)以及操作符等。
实现机制:词法分析器通常基于确定性有限自动机(DFA)或非确定性有限自动机(NFA)来解析正规文法。
输入数据包括正规文法产生式和源代码字符串。
输出则是一个符号表,其中包含五种类型的符号:关键词、标识符、常量、界符和操作符。
实现步骤:首先,从文本文件中读取预定义的文法,并将其转换为NFA。
接着,应用子集法将NFA转换为DFA。
然后,对源程序进行逐字符扫描,利用DFA判断字符的合法性,并输出词法分析结果。
关键函数:createNFA()用于从文本文件创建文法并引入程序;showNFA()用于展示NFA;Is_in(NFA_settemp)用于判断新产生的子集是否已存在;get_closure(NFA_set&temp)用于计算ε-closure;Is_contained_Y(NFA_settemp)用于判断状态是否为终态;NFA_to_DFA()是NFA转换为DFA的关键;DFA(charstr[])用于判断字符串是否由DFA表示;scan()用于扫描源程序并输出词法分析结果。
语法分析器:作为编译器的另一核心组件,语法分析器的职责是依据上下文无关文法(2 型文法)检查词法分析器输出的符号表,以验证源代码字符串是否符合该文法。
实现机制:语法分析器通常采用LL(1 )或LR(1 )方法。
输入为包含2 型文法产生式和符号表的文本文档,输出为YES或NO,表示源代码字符串是否符合该文法。
实现步骤:首先,从文本文件中读取2 型文法并存储于数据结构中。
计算first集,确定每个非终结符可能开始的终结符集合。
求解LR(1 )项目集族,构建LR(1 )分析表。
利用分析表对输入符号表进行语法分析,以判断源代码字符串是否符合文法。
关键函数:get_grammar()用于读取文法;get_first()用于计算first集;write_first_set()将first集写入文本文件;gete_search(projecttemp)用于获取向前搜索符;is_in(projecttemp,intT)用于判断项目集元素是否重复;e_closure(intT)用于求解项目集族;is_contained()用于判断项目集是否重复;make_set()用于构建项目集;get_action()用于构建分析表;judge()用于判断句子是否属于该文法的语言。
示例与图片展示:在词法分析中,NFA到DFA的转换是关键步骤。
以下为NFA到DFA转换的示例图。
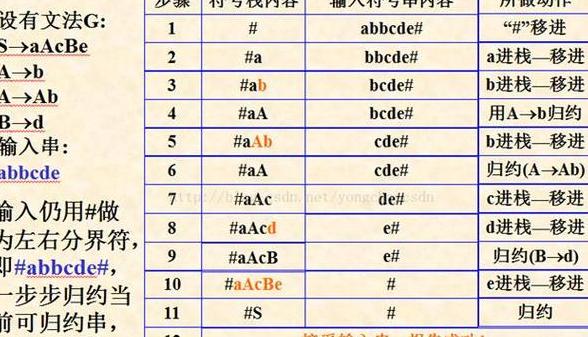
在语法分析中,LR(1 )分析表的构建是核心环节。
以下为LR(1 )分析表的示例图。
通过分析表,语法分析器可以逐步分析输入符号表,最终确定源代码字符串是否符合给定的2 型文法。
若分析成功,则输出YES;若失败,则输出NO,并提供错误信息以辅助用户定位问题。
总结:词法分析器和语法分析器是编译器不可或缺的组成部分,它们负责将源代码字符串分解为词法单元,并验证这些单元是否符合给定的上下文无关文法。
通过实现这两个组件,我们可以对C语言等编程语言的源代码进行深入分析,为后续的语义分析、代码生成等步骤奠定坚实基础。